Co-Lab is a tool initiated by the Government of Canada’s National Library and Archives (LAC) that allows crowd-sourcing transcriptions, tags, translations, and descriptions on digitized sources. The LAC explains the key motivations for the project were to increase the accessibility of these documents to researchers by making the images highly searchable, and to the visually impaired by allowing these images to be read by screen-readers.
The process to digitize items is labour intensive and notoriously slow, therefore the LAC must carefully choose what to digitize and, importantly, when. Many of these items were deliberately chosen to coincide with their centennial anniversaries, a common milestone for the Canadian government to commemorate. These include the “Spanish Flu Pandemic of 1918-1919” project, which included 117 images to transcribe and has since been completed. Similarly, “The Call to Duty: Canada’s Nursing Sisters” and “War Diaries of the First World War: 1st Canadian Division” commemorate the end of World War I. Others were chosen for their remarkable content, usually original photos and exceptional experiences: “Rosemary Gilliat (Eaton)’s Arctic diary and photographs”, “Japanese-Canadians: Second World War” and “Legendary train robber and prison escapee Bill Miner” and examples of this.
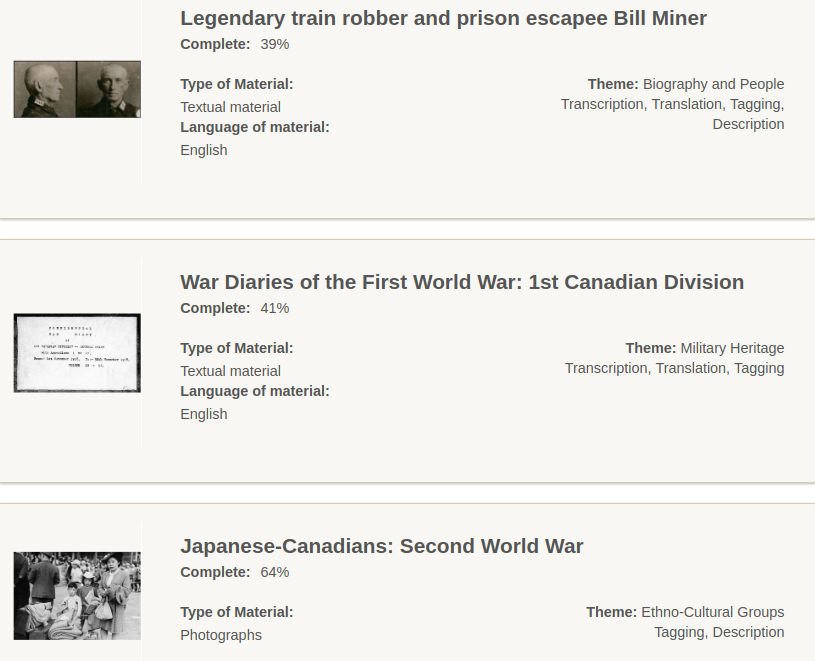
The LAC titles these projects as “Challenges” and asks the public to crowd-source various types of data (bottom right corner in above image) that is needed for the challenge to be completed. These include, as seen above: tagging, transcriptions, translations (English to French; French to English), and descriptions. The process is simple enough, once a user has provided the required data, they manually mark the image or scan as “completed”, “needs review”, or “incomplete” so that the next users can identify the status of an item in the larger challenge. The image below depicts what this looks like from the item overview:

https://co-lab.bac-lac.gc.ca/eng/Tasks/Details/1015
So what does this process look like? I encourage you to click on the image above and select an item to follow along with. For now, an incomplete task page looks like this:
Note the transcription area (right of scan) is blank. The transcription status is set to “Not Started”. Both of these elements are community contributed content and are largely unmoderated. That is, the general population is encourage to add, edit, and moderate this content themselves. Clearly, the pessimists among us will already see the issue: what if one user, intentionally or unintentionally, deletes or falsifies this data? What mechanisms are in place to ensure crowd sourcing goes as planned? The answer, somewhat strangely, is that there is none. Surely a user would be shamed into not intentionally participating in erroneous behaviour, but, the website allows users to contribute anonymously, removing that element. Thus, the mechanism is the contributing population itself. It is a self-regulating community. But I suspect there is more to it than this. The project is by no means public knowledge, and I believe that the platform benefits from this lack of knowledge. Unlike similar community contribution run websites such as Reddit, a widely used collection of forums that allow millions to engage with content from across the web daily, LAC’s Co-Lab project enjoys a more obscure status, lending itself to the academic community rather than the general population. So, where we get the infamous “internet trolls” on popular sites (see YouTube, Facebook), the relative anonymity of the Co-Lab project allows for a smoother, but perhaps slower, process of crowd-sourcing data.
Now that the contributor has situated themselves with the image and transcription box, they can begin to transcribe. The LAC has implemented an OpenSeadragon viewer to allow for high resolution zoom-ins of the items for easier transcription. It looks like this:

Instantly one can see the benefit of this tool for transcription. The zoom allows you to see the letter forms up close and with high definition, allowing the transcriber to leave their magnifying glass at the door. The benefit of OpenSeadragon over another zoom tool is that it only renders the requested segment of the image. This means the user only downloads the information for a small piece of the entire canvas at a time, reducing loading time while still allowing for incredibly high resolution zooms. This increases accessibility to all Co-Lab users, even those on machines with low processing specs or those with slow internet connections.
Having discussed the framework, it was time to begin the process of transcription. Continuing with Image 215, I transcribed the manuscript the way I was trained. The result below took about five minutes to accomplish:
But LAC has outlined guidelines for transcription that do not necessarily follow the training I have received. I compared the guidelines, and found several places that needed adjustment in order to properly contribute to the project, chiefly:
- Indicate words that you are unsure of by using the term “illegible” or a question mark inside two sets of square brackets. Example: [[illegible]] or [[?]].
- If you can decipher a portion of the word, include it followed by a question mark inside two sets of square brackets. Example: [[immediate?]], [[-ing?]], [[name?]], etc.
- […]
- Do not worry about the formatting, such as text alignment, columns, line breaks, spacing, etc.
—from: Co-Lab, Guidelines, Transcription Guidelines
After fixing these issues to more closely fit the guidelines of the Co-Lab project, the transcription looked like this:
In the process, I was able to research and correctly identify a few of the words such as “saxifrage” and “cinquefoil”. I changed the status of the transcription from “Incomplete” to “Needs Review” and provided some appropriate tags:
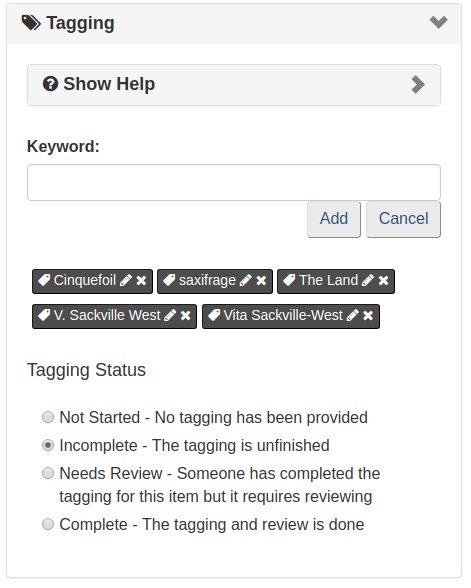
Altogether, the process to contribute to these challenges was made easy by the guidelines and tutorials provided by Co-Lab. The implementation of the OpenSeadragon viewer gives access to anyone with access to a computer and an internet connection. Despite this, it is not widely popular, a fact that I believe helps Co-Lab reach its crowd-sourcing goal more than it hinders. The LAC put forth these challenges in order to both provide the public full digital access to these interesting pieces of history and have them transcribed, tagged, translated, and described by those same people. Had a department (or a single researcher) in the LAC been in charge of providing this same data, the process would have likely taken years, or perhaps these items may have never made it to the digitization lab. This crowd-sourcing endeavour demonstrates the living nature of historical documents and images, and gives shared authority and access to the public. I am eager to see where the LAC’s Co-Lab project goes next.
Works Cited & Web Resources
Cataloguing Medieval Manuscripts. (2013). Crowdsourcing the Arcane: Utilizing Flickr (and Google) to Describe Medieval Manuscript Fragments. Retrieved from:
https://micahcapstone.wordpress.com/category/uncategorized/
Accessed to get a quick understanding of the process and trials of similar crowdsourcing projects.
Library and Archives Canada. (2019). Co-Lab: Your Collaboration Tool. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng
Library and Archives Canada. (2019). Co-Lab: About Co-Lab. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng/About
Library and Archives Canada. (2019). Co-Lab: Challenges. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng/Challenges
Library and Archives Canada. (2019). Co-Lab: Rosemary Gilliat (Eaton)’s Arctic diary and photographs. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng/Challenges/Details/1009
Library and Archives Canada. (2019). Co-Lab: Rosemary Gilliat (Eaton)’s Arctic diary. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng/Tasks/Details/1015
Library and Archives Canada. (2019). Co-Lab: Rosemary Gilliat (Eaton)’s Arctic diary: Image 215. Retrieved from:
https://co-lab.bac-lac.gc.ca/eng/Objects/Contribute/e011181043-215?gid=1015
OpenSeadragon. (2013). OpenSeadragon 4.2.0. Retrieved from:
https://openseadragon.github.io/